ИИ Microsoft способен имитировать голос человека по трехсекундному образцу - «Новости»
- 10:30, 13-янв-2023
- Новости / Изображения / Текст / Блог для вебмастеров / Преимущества стилей / Заработок / Отступы и поля / Самоучитель CSS / Вёрстка / Сайтостроение
- Cook
- 0
Инженеры Microsoft представили модель искусственного интеллекта для преобразования текста в речь (text-to-speech) под названием VALL-E. Она способна имитировать голос человека, опираясь лишь на трехсекундный звуковой образец. Разработчики утверждают, что VALL-E может синтезировать аудио, где «выученный» голос что-либо говорит, при этом сохранив даже эмоциональную окраску.
Создатели называют VALL-E «языковой моделью нейронных кодеков» (neural codec language model) и полагают, что новинку можно будет использовать для работы высококачественных text-to-speech приложений, редактирования речи, когда запись речи может быть отредактирована и изменена из текстовой расшифровки (то есть человек «скажет» то, чего изначально не говорил), а также создания аудиоконтента в сочетании с другими генеративными моделями ИИ, такими как GPT-3 (стоящая за нашумевшим ChatGPT).
VALL-E строится на базе технологии EnCodec, которую Meta* анонсировала в октябре 2022 года. В отличие от других методов преобразования текста в речь, VALL-E генерирует дискретные коды аудиокодеков из текста и полученных акустических подсказок. По сути, VALL-E анализирует, как звучит человек, благодаря EnCodec разбивает эту информацию на дискретные компоненты (называемые «токенами») и использует обучающие данные, сопоставляя то, что «знает» о том, как бы звучал этот голос, если бы он произносил другие фразы за пределами трехсекундного образца.
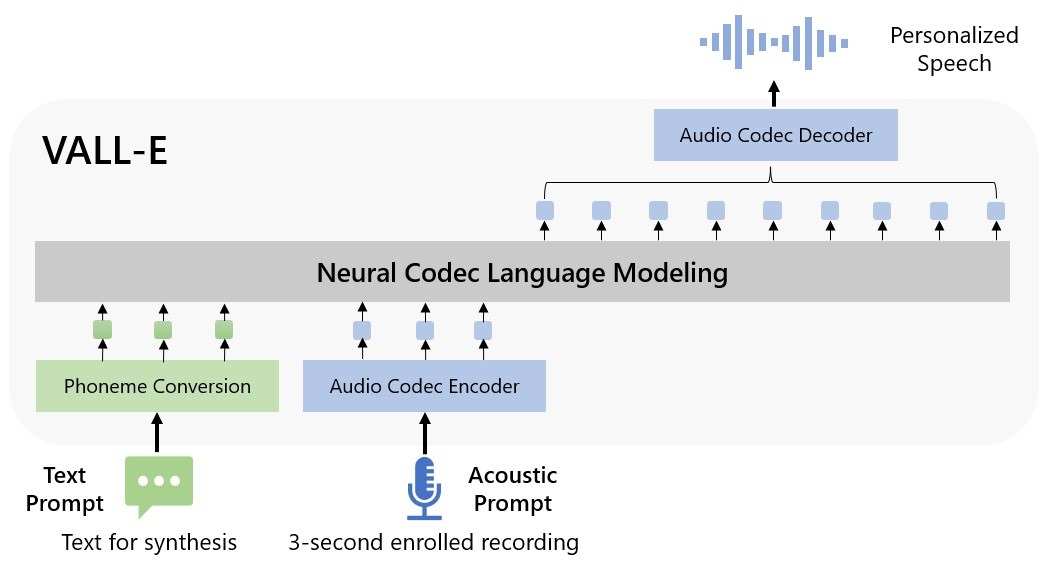
Специалисты Microsoft обучали VALL-E синтезу речи на звуковой библиотеке LibriLight, которая содержит 60 000 часов англоязычной речи более чем 7 000 носителей (в основном взятых из общедоступных аудиокниг на LibriVox). Чтобы VALL-E показывала хороший результат, голос в трехсекундном образце должен быть похож на голос из этих обучающих данных.
На специальном сайте Microsoft приводит десятки примеров работы VALL-E. Интересно, что помимо сохранения тембра и эмоционального тона говорящего, VALL-E также может имитировать «акустическое окружение» из аудиообразца. То есть, если сэмпл взят, к примеру, из телефонного звонка, версия VALL-E тоже может звучать как запись звонка, со всеми соответствующими искажениями и нюансами.
Так как VALL-E явно может использоваться для самых разных злоупотреблений и мошенничества, пока Microsoft не публикует исходный код своей разработки и отмечает, что в будущем можно создать модель для обнаружения аудиоконтента, сгенерированного при помощи VALL-E.
* Meta Platforms признана экстремистской организацией и ее деятельность запрещена в России
















Комментарии (0)