Рано или поздно на смену жёстким дискам и SSD придут новые виды носителей данных, на что намекает экспоненциальный рост объёмов информации. Для этого уже сейчас учёные бьются над проблемами записи на молекулярном уровне, и определённые успехи на этом направлении есть.
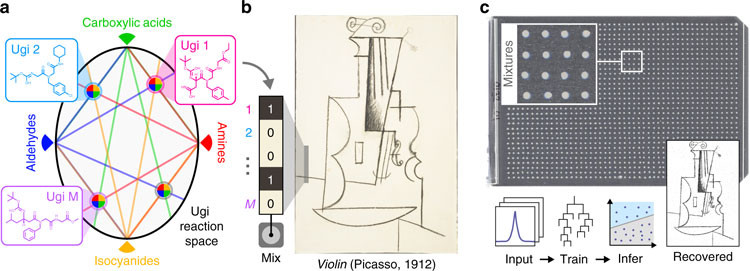
Группа учёных из Университета Брауна (США) сообщила о прогрессе в разработке методов записи и считывания данных на молекулярном уровне. Данные об исследовании опубликованы в Nature Communications (статья доступна для бесплатного прочтения на английском языке). В серии экспериментов учёные записали, сохранили и затем считали цифровые файлы с закодированными изображениями египетского бога Анубиса, абстрактной картины скрипки Пикассо и другие изображения общим объёмом 200 Кбайт.
Это не первая попытка закодировать данные с помощью набора молекул, но в данном случае учёные решили не ждать милости от природы. До данного эксперимента учёные брали известные химические соединения (молекулы) и создавали из них смеси - таким образом кодировали входящие данные. Считывание данных происходит с помощью последовательного анализа смесей масс-спектрометром. Затем компьютерная программа преобразует полученный результат в картинку или текст. Подобный подход был ограничен известным химикам набором небольших по размеру молекул. А чем меньше молекул, тем меньше возможностей для кодирования, например, с точки зрения разрядности.
Учёные из Университета Брауна синтезировали собственные наборы молекул - библиотеки для кодирования данных. Вся хитрость заключалась в том, чтобы из простейших соединений и без сложных реакций научиться быстро создавать библиотеки из простых молекул, которые масс-спектрометр мог бы идентифицировать с максимальной точностью.
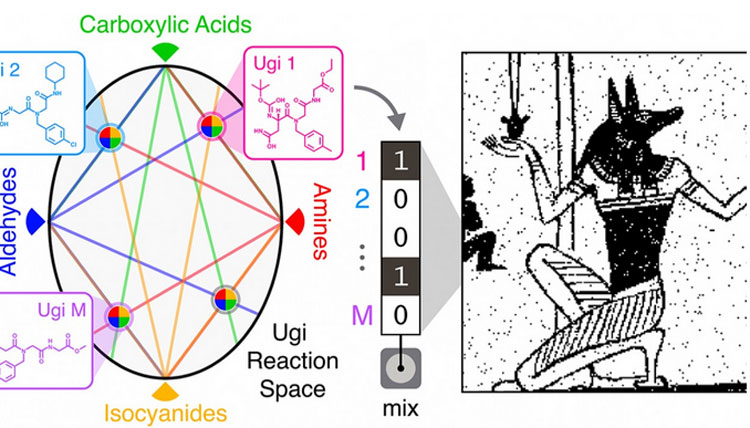
Для синтеза малых молекул была выбрана так называемая Уги реакция - это многокомпонентная комбинаторная реакция с использованием четырёх компонентов: карбоновой кислоты, амина, альдегида (кетона) и изоцианида. Эта реакция широко используется в фармацевтике и является надёжным инструментом для синтеза соединений. Для создания библиотек из молекул в различных комбинациях использовались пять аминов, пять альдегидов, 12 карбоновых кислот и пять изоцианидов. Всего учёные смогли создать до 1500 соединений.
Преимуществом здесь является потенциальная масштабируемость библиотеки. Используя всего 27 различных компонентов, учёные за один день создали библиотеку из 1500 молекул и им не пришлось искать для этого какие-либо уникальные молекулы.
Для кодирования каждой картинки использовались свои библиотеки в виде уникального набора из молекул. Для записи изображения Анубиса, например, библиотека содержала 32 компонента. Для кодирования 0,88-мегапиксельного рисунка Пикассо была задействована библиотека из 575 соединений.
Технически запись происходила следующим образом. Данные кодировались в смеси молекул, которые помещались в крохотные лунки диаметром менее миллиметра на небольших пластинках из железа. В каждой лунке (капле) уникальных молекул может быть так же много, как в библиотеке. Например, в самом максимальном случае - 1500, но надёжно считать их все в такой комбинации пока нельзя. Тем не менее, это позволяет судить о разрядности каждой смеси, а она ограничена только размерами библиотеки. Затем каждая смесь считывается масс-спектрометром, молекулы идентифицируются и входящие данные расшифровываются.
Для представленного метода учёным пришлось разрабатывать алгоритмы коррекции ошибок. Разработанный метод позволил идентифицировать молекулы с точностью до 99 %. Метод доказал свою надёжность, но исследования необходимо продолжить.
Рано или поздно на смену жёстким дискам и SSD придут новые виды носителей данных, на что намекает экспоненциальный рост объёмов информации. Для этого уже сейчас учёные бьются над проблемами записи на молекулярном уровне, и определённые успехи на этом направлении есть. Группа учёных из Университета Брауна (США) сообщила о прогрессе в разработке методов записи и считывания данных на молекулярном уровне. Данные об исследовании опубликованы в Nature Communications (статья доступна для бесплатного прочтения на английском языке). В серии экспериментов учёные записали, сохранили и затем считали цифровые файлы с закодированными изображениями египетского бога Анубиса, абстрактной картины скрипки Пикассо и другие изображения общим объёмом 200 Кбайт. Это не первая попытка закодировать данные с помощью набора молекул, но в данном случае учёные решили не ждать милости от природы. До данного эксперимента учёные брали известные химические соединения (молекулы) и создавали из них смеси - таким образом кодировали входящие данные. Считывание данных происходит с помощью последовательного анализа смесей масс-спектрометром. Затем компьютерная программа преобразует полученный результат в картинку или текст. Подобный подход был ограничен известным химикам набором небольших по размеру молекул. А чем меньше молекул, тем меньше возможностей для кодирования, например, с точки зрения разрядности. Учёные из Университета Брауна синтезировали собственные наборы молекул - библиотеки для кодирования данных. Вся хитрость заключалась в том, чтобы из простейших соединений и без сложных реакций научиться быстро создавать библиотеки из простых молекул, которые масс-спектрометр мог бы идентифицировать с максимальной точностью. Для синтеза малых молекул была выбрана так называемая Уги реакция - это многокомпонентная комбинаторная реакция с использованием четырёх компонентов: карбоновой кислоты, амина, альдегида (кетона) и изоцианида. Эта реакция широко используется в фармацевтике и является надёжным инструментом для синтеза соединений. Для создания библиотек из молекул в различных комбинациях использовались пять аминов, пять альдегидов, 12 карбоновых кислот и пять изоцианидов. Всего учёные смогли создать до 1500 соединений. Преимуществом здесь является потенциальная масштабируемость библиотеки. Используя всего 27 различных компонентов, учёные за один день создали библиотеку из 1500 молекул и им не пришлось искать для этого какие-либо уникальные молекулы. Для кодирования каждой картинки использовались свои библиотеки в виде уникального набора из молекул. Для записи изображения Анубиса, например, библиотека содержала 32 компонента. Для кодирования 0,88-мегапиксельного рисунка Пикассо была задействована библиотека из 575 соединений. Технически запись происходила следующим образом. Данные кодировались в смеси молекул, которые помещались в крохотные лунки диаметром менее миллиметра на небольших пластинках из железа. В каждой лунке (капле) уникальных молекул может быть так же много, как в библиотеке. Например, в самом максимальном случае - 1500, но надёжно считать их все в такой комбинации пока нельзя. Тем не менее, это позволяет судить о разрядности каждой смеси, а она ограничена только размерами библиотеки. Затем каждая смесь считывается масс-спектрометром, молекулы идентифицируются и входящие данные расшифровываются. Для представленного метода учёным пришлось разрабатывать алгоритмы коррекции ошибок. Разработанный метод позволил идентифицировать молекулы с точностью до 99 %. Метод доказал свою надёжность, но исследования необходимо продолжить.
Новости / Отступы и поля / Самоучитель CSS / Преимущества стилей / Ссылки / Сайтостроение / Видео уроки / Добавления стилей / Линии и рамки / Изображения / CSS3
Вслед за недавним тизером разработчики из американской студии Riot Games (принадлежит китайскому IT-гиганту Tencent) поделились подробностями League of Legends Classic...
Разработчики из принадлежащей Sony Interactive Entertainment американской Santa Monica Studio косвенно подтвердили сроки выхода анонсированного недавно приключенческого...
Пользователь Reddit с ником Ordo_Liberal заявил, что ему удалось выиграть судебное разбирательство против Microsoft. В его сообщении сказано, что бразильский суд обязал...
Разработчики из американской студии Refugium Games объявили точную дату выхода своего школьного экшена с открытым миром Agefield High: Rock the School в духе...


















Комментарии (0)